
Jia Jia, PhD
PROFESSOR OF COMPUTER SCIENCE

Jia Jia, PhD
PROFESSOR OF COMPUTER SCIENCE
Major Awards more
2024
Supported by the National Science Fund for Distinguished Young Scholars, 2024
国家杰出青年科学基金获得者(2024)
2024
Pioneer in Management and Education Award, Beijing Education System, 2024
北京市教育系统“管理育人先锋”(2024)
2024
NeurIPS 2024 Spotlight Award, 2024
2023
Best Paper Award, China Multimedia Conference (ChinaMM), 2023
中国多媒体大会最佳论文奖(2024)
2022
Second Prize in National Teaching Achievement Award in Higher Education, 2022
高等教育国家级教学成果二等奖(2022)
2022
First Prize of Teaching Award in Beijing Higher Education, 2022
北京市高等教育教学成果奖一等奖(2022)
2021
Award of Outstanding Scientific and Technological Achievement in the Chinese Association for Artificial Intelligence (CAAI), 2021
中国人工智能学会CCAI 2021年度优秀科技成果奖(2021)
2020
Supported by Young Changjiang Scholars Program of China, 2020
教育部“长江学者奖励计划”青年学者(2020)
2019
First Prize of Scientific and Technological Progress in the Chinese Institute of Electronics(CIE), 2019
中国电子学会科技进步一等奖(2019)
2018
ACM SIGMM Emerging Leaders, 2018
2018
ACM Multimedia Best Demo Award, 2018
2018
IJCAI Early Career Spotlight, 2018
About me more

Jia Jia
Tenure Professor
Contact:
Office:
Biography:
Research Interests
Selected Publications more
Recent Conference Papers
Recent Journals
Teaching Statement more
Demo more

 HoloSinger: Semantics and Music Driven Motion Generation with Octahedral Holographic Projection. MM'23
HoloSinger: Semantics and Music Driven Motion Generation with Octahedral Holographic Projection. MM'23
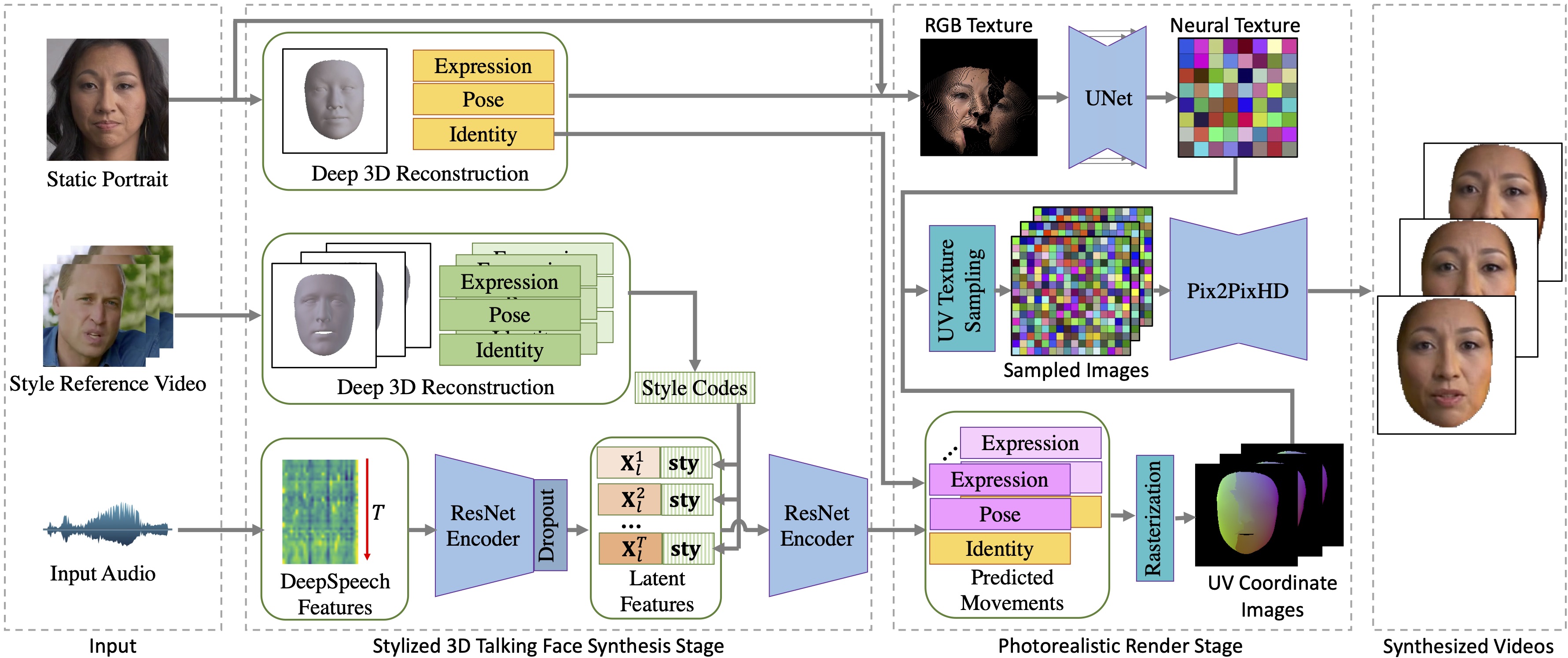
Imitating Arbitrary Talking Style for Realistic Audio-Driven Talking Face Synthesis. MM'21

ChoreoNet: Towards Music to Dance Synthesis with Choreographic Action Unit. MM'20 Oral

AniDance: Real-Time Dance motion synthesize to the Song. MM'18 Best Demo